2024.09.20 - [RAG Project] - [RAG Project] GlobalMacro QA chatbot - Question Process&Evaluation (8)
[RAG Project] GlobalMacro QA chatbot - Question Process&Evaluation (8)
2024.09.17 - [RAG Project] - [RAG Project] GlobalMacro QA chatbot - Retriever&Evaluation (7) [RAG Project] GlobalMacro QA chatbot - Retriever&Evaluation (7)2024.09.12 - [RAG Project] - [RAG Project] GlobalMacro QA chatbot - Embedding&Vectorstore (6) [RAG
hibyeys.tistory.com
지난번 포스팅에서 질문 프로세스를 정의하고 테스트 데이터셋을 직접만들어 chain 평가를 수행하였다.
이번 시간에는 best chain에 rerank module을 추가해 langsmith를 통해 추가적인 평가를 수행해 보겠다.
1. Reranker
1.1 기존 RAG의 문제
RAG 는 수많은 텍스트 문서에서 Semactic Search 활용된다.
Semantic Search에는 보통 벡터 검색이 활용되는데, 여기서 정보 손실이 발생한다.
한번은 문서의 Embedding 과정에서 일어나고 한번은 검색 과정에서 일어난다.
이러한 정보 손실로 인해 LLM으로 전달되는 상위 k개의 문서내의 정보가 누락되는 경우가 발생하게 된다.
이러한 문제를 검색 후 반환되는 문서수를 늘려 간단하 해결할 수 있지만 LLM에 전달하는 context가 늘어나
비용 측면에서 효율적이지 않다.
또한 최근 논문에 따르면 RAG의 정확도는 관련 정보가 context 내의 존재 유무가 아니라 순서라고 밝혀졌다. (논문 링크)
논문에 따르면 관련 깊은 문서가 입력의 초반 혹은 후반에 위치할수록 성능이 좋다고 한다. (논문 제목이 Lost in the middle이다)
1.2 Reranker 란?
위의 문제점을 개선하기 위해 나온것이 바로 Reranker 이다.
Reranker 도 기본적으로 질문과 문서 사이의 유사도를 측정하는 모듈이다.
하지만 질문과 문서에 대한 독립적인 임베딩을 활용하는 Bi-encoder 형태의 벡터 검색과 다르게
질문과 문서를 하나의 인풋으로 활용하는 Cross-encoder 형태로 검색을 수행한다.
그로인해 질문과 문서를 동시에 분석함으로써, Bi-encoder 방식에 비해 더욱 정확한 유사도 측정이 가능하다.
하지만 그만큼 연산이 굉장히 오래걸리는 문제 때문에 아래와 같이 두 가지 방식을 나누어 사용한다.
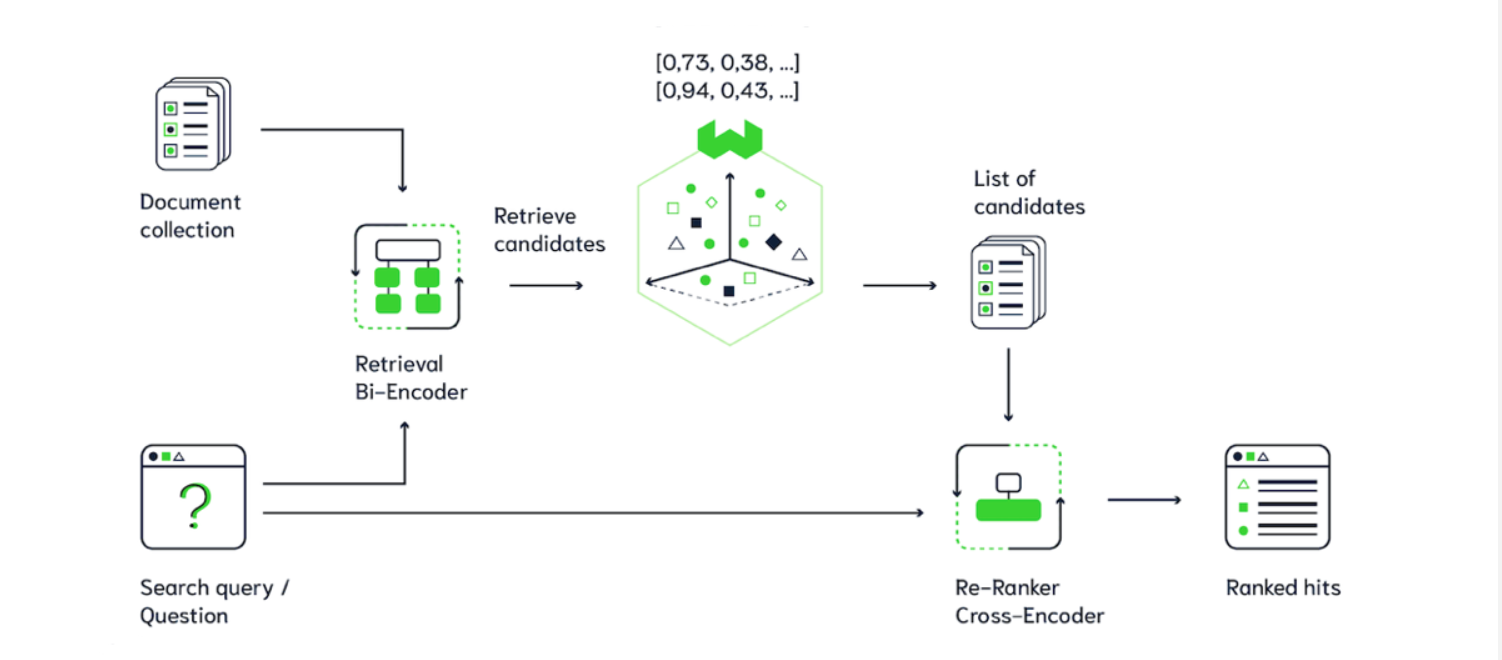
첫번째 단계에서는 기존의 벡터 검색 방식으로 후보군을 검색하고
두번째 단계에서 검색된 문서들에 대해 Reranker 기반으로 관련성을 재측정 한다.
이렇게 사용하면 문서의 검색속도를 높이면서도 질문과의 관련성을 정확히 측정하는 것이 가능해진다.
1.3 Reranker의 종류
아래는 AutoRAG에서 제공하는 Reranker들이다.

이외에도 많은 reranker 모델들이 있지만
저 중에서 api 로 사용하면서 한국어 성능이 괜찮다고 알려진 cohere_reranker, jina_reranker 와
오픈 소스 모델인 bge-reranker-v2-m3, 그리고 BAAI/bge-reranker-larger 를
한국어로 Fine-Tuning 한 Ko-reranker를 테스트 해볼 것이다.
1.4 Test

평균 점수를 보면 rerank를 안쓴것이 오히려 성능이 괜찮아 보인다. 나중에 chatbot에 reranker 옵션도 붙여서 정성적인 테스트도 같이 실행해보아야겠다.
2. more Evaluation with Langsmith
Langsmith에도 평가 기능들이 잘 제공되어 있어서 이번에는 Langsmith에서 제공하는 Evaluation 기능을 사용해 평가를 진행해 보았다.
아래는 그냥 BM25 , cohere, jina, bge, ko-reranker 순으로 테스트를 진행한 결과이다.

전반적으로 성능이 나쁘지 않지만 Ground_Truth 와 Answer 의 유사성을 측정하는 지표에서 Cohere 모델을 사용하였을 때 점수가 올라가는 것을 볼 수 있었고 Correctness도 reranker를 안쓸때보다 점수가 높다.